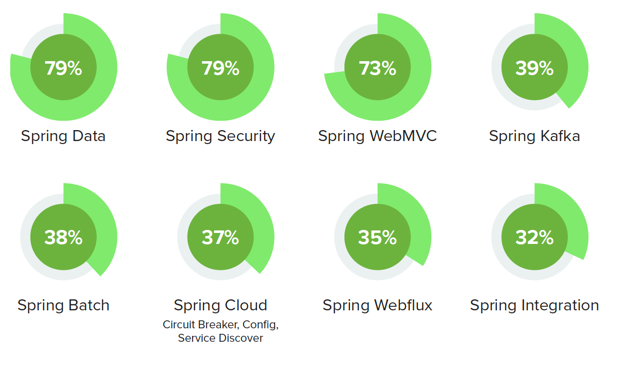
I got a chance to look at this year's State of Spring Report from VMware Tanzu, and I've summarized what I've found interesting so my readers can get the TL;DR (from my opinionated position).
spring
AOP Caching
Today I would like to document my experiences implementing caching with Aspect Oriented Programming (AOP) and annotations.
Validation with Spring Modules Validation
So if java generics slightly disappointed me lately, what have I found cool? I’m currently working on a web application using Spring MVC, which probably doesn’t come as a big surprise, it seems to be all the rage these days. Since this is my baby, I got to call the shots as to a lot … Read more