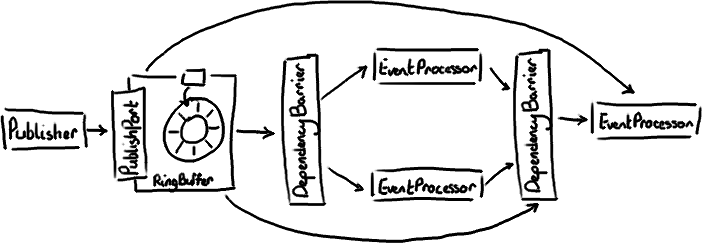
Martin recently announced version 2.0 of the Disruptor - basically there have been so many changes since we first open-sourced it that it's time to mark that officially. His post goes over all the changes, the aim of this article is to attempt to translate my previous blog posts into new-world-speak, since it's going to take a long time to re-write each of them all over again. Now I see the disadvantage of hand-drawing everything.
Month: August 2011
What I Did On My Holidays

And now, a post for my long-neglected, less technical readers.
I took a week off in July to try and avoid that Oh My God I Missed Summer Again feeling. Granted, it's easy to get that in the UK even if you're not stuck in an office the entire time.
Really this is just an excuse to post some photos on the blog.
Dissecting the Disruptor: Demystifying Memory Barriers
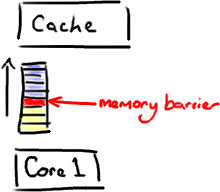
My recent slow-down in posting is because I've been trying to write a post explaining memory barriers and their applicability in the Disruptor. The problem is, no matter how much I read and no matter how many times I ask the ever-patient Martin and Mike questions trying to clarify some point, I just don't intuitively grasp the subject. I guess I don't have the deep background knowledge required to fully understand.
So, rather than make an idiot of myself trying to explain something I don't really get, I'm going to try and cover, at an abstract / massive-simplification level, what I do understand in the area. Martin has written a post going into memory barriers in some detail, so hopefully I can get away with skimming the subject.