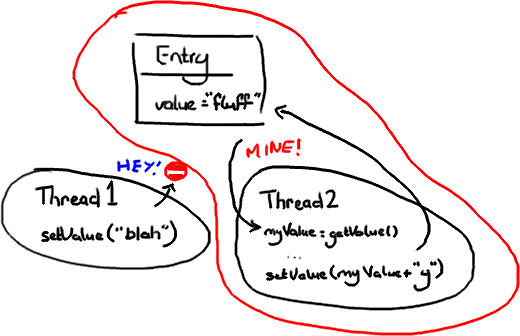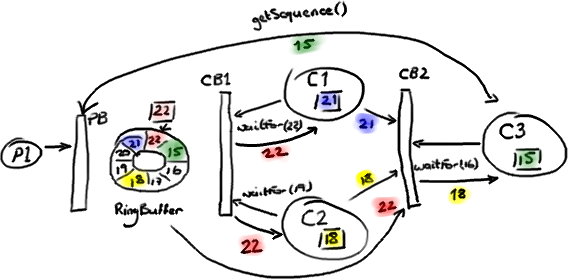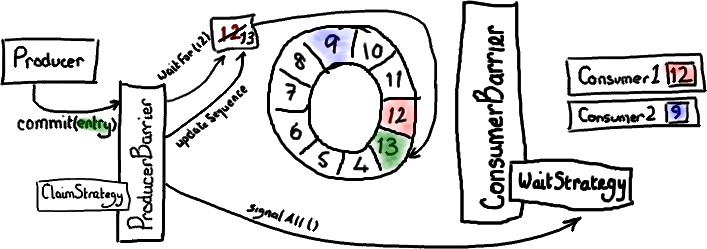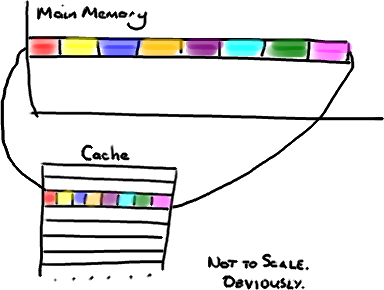
We mention the phrase Mechanical Sympathy quite a lot, in fact it's even Martin's blog title. It's about understanding how the underlying hardware operates and programming in a way that works with that, not against it.
We get a number of comments and questions about the mysterious cache line padding in the RingBuffer, and I referred to it in the last post. Since this lends itself to pretty pictures, it's the next thing I thought I would tackle.
Continue reading "Dissecting the Disruptor: Why it’s so fast (part two) – Magic cache line padding"