Recently we open sourced the LMAX Disruptor, the key to what makes our exchange so fast. Why did we open source it? Well, we've realised that conventional wisdom around high performance programming is... a bit wrong. We've come up with a better, faster way to share data between threads, and it would be selfish not to share it with the world. Plus it makes us look dead clever.
On the site you can download a technical article explaining what the Disruptor is and why it's so clever and fast. I even get a writing credit on it, which is gratifying when all I really did is insert commas and re-phrase sentences I didn't understand.
However, I find the whole thing a bit much to digest all at once, so I'm going to explain it in smaller pieces, as suits my NADD audience.
First up - the ring buffer. Initially I was under the impression the Disruptor was just the ring buffer. But I've come to realise that while this data structure is at the heart of the pattern, the clever bit about the Disruptor is controlling access to it.
What on earth is a ring buffer?
Well, it does what it says on the tin - it's a ring (it's circular and wraps), and you use it as a buffer to pass stuff from one context (one thread) to another:
(OK, I drew it in Paint. I'm experimenting with sketch styles and hoping my OCD doesn't kick in and demand perfect circles and straight lines at precise angles).
So basically it's an array with a pointer to the next available slot.
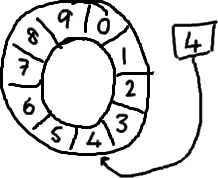
As you keep filling up the buffer (and presumable reading from it too), the sequence keeps incrementing, wrapping around the ring:
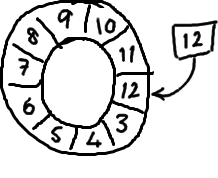
To find the slot in the array that the current sequence points to you use a mod operation:
sequence mod array length = array indexSo for the above ring buffer (using Java mod syntax): 12 % 10 = 2. Easy.
Actually it was a total accident that the picture had ten slots. Powers of two work better because computers think in binary.
So what?
If you look at Wikipedia's entry on Circular Buffers, you'll see one major difference to the way we've implemented ours - we don't have a pointer to the end. We only have the next available sequence number. This is deliberate - the original reason we chose a ring buffer was so we could support reliable messaging. We needed a store of the messages the service had sent, so when another service sent a nak to say they hadn't received some messages, it would be able to resend them.
The ring buffer seems ideal for this. It stores the sequence to show where the end of the buffer is, and if it gets a nak it can replay everything from that point to the current sequence:
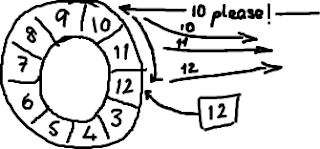
The difference between the ring buffer as we've implemented it, and the queues we had traditionally been using, is that we don't consume the items in the buffer - they stay there until they get over-written. Which is why we don't need the "end" pointer you see in the Wikipedia version. Deciding whether it's OK to wrap or not is managed outside of the data structure itself (this is part of the producer and consumer behaviour - see my later blogs).
And it's so great because...?
So we use this data structure because it gives us some nice behaviour for reliable messaging. It turns out though that it has some other nice characteristics.
Firstly, it's faster than something like a linked list because it's an array, and has a predictable pattern of access. This is nice and CPU-cache-friendly - at the hardware level the entries can be pre-loaded, so the machine is not constantly going back to main memory to load the next item in the ring.
Secondly, it's an array and you can pre-allocate it up front, making the objects effectively immortal. This means the garbage collector has pretty much nothing to do here. Again, unlike a linked list which creates objects for every item added to the list - these then all need to be cleaned up when the item is no longer in the list.
The missing pieces
I haven't talked about how to prevent the ring wrapping, or specifics around how to write stuff to and read things from the ring buffer. You'll also notice I've been comparing it to a data structure like a linked list, which I don't think anyone believes is the answer to the world's problems.
The interesting part comes when you compare the Disruptor with an implementation like a queue. Queues usually take care of all the stuff like the start and end of the queue, adding and consuming items, and so forth. All the stuff I haven't really touched on with the ring buffer. That's because the ring buffer itself isn't responsible for these things, we've moved these concerns outside of the data structure.
For more details you're just going to have to read the paper or check out the code. Or watch Mike and Martin at QCon San Francisco last year. Or take a look at some of [my other disruptor blogs].(https://github.com/LMAX-Exchange/disruptor/)