Martin recently announced version 2.0 of the Disruptor - basically there have been so many changes since we first open-sourced it that it's time to mark that officially. His post goes over all the changes, the aim of this article is to attempt to translate my previous blog posts into new-world-speak, since it's going to take a long time to re-write each of them all over again. Now I see the disadvantage of hand-drawing everything.
In the old world

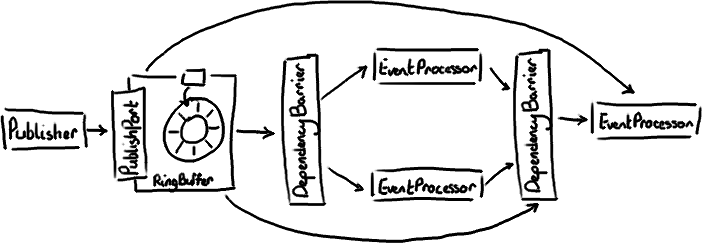
This is an example of a configuration of the Disruptor (specifically a diamond configuration). If none of this means anything to you, feel free to go back and refresh yourself on all the (now outdated) Disruptor details.
The most obvious changes over the last few weeks have been:
- Updated naming convention
- Integrating the producer barrier into the ring buffer
- Adding the Disruptor wizard into the main code base.
The New World Order

You'll see the fundamentals are pretty much the same. It's simpler, because the ProducerBarrier is no longer an entity in its own right - its replacement is the PublishPort interface, which is implemented by the RingBuffer itself.
Similarly the name DependencyBarrier instead of ConsumerBarrier clarifies the job of this object; Publisher (instead of Producer) and EventProcessor instead of Consumer also more accurately represent what these things do. There was always a little confusion over the name Consumer, since consumers never actually consumed anything from the ring buffer. It was simply a term that we hoped would make sense to those who were used to queue implementations.
Not shown on the diagram is the name change of the items in the RingBuffer - in the old world, we called this Entry, now they're an Event, hence EventProcessor at the other end.
The aim of this wholesale rename has not been to completely discredit all my old blogs so I can continue blogging about the Disruptor ad infinitum. This is far from what I want - I have other, more fluffy, things to write about. The aim of the rename is to make it easier to understand how the Disruptor works and how to use it. Although we use the Disruptor for event processing, when we open sourced it we wanted it to look like a general purpose solution, so the naming convention tried to represent that. But in fact the event processing model does seem more intuitive.
No more tedious wiring
Now the Disruptor wizard is part of the Disruptor itself, my whole post on wiring is pretty pointless - which is good, actually, because it was a little involved.
These days, if you want to create the diamond pattern (for example the FizzBuzz performance test), it's a lot simpler:
DisruptorWizard dw = new DisruptorWizard<FizzBuzzEvent>(ENTRY_FACTORY,
RING_BUFFER_SIZE,
EXECUTOR,
ClaimStrategy.Option.SINGLE_THREADED,
WaitStrategy.Option.YIELDING);
FizzBuzzEventHandler fizzHandler = new FizzBuzzEventHandler(FIZZ);
FizzBuzzEventHandler buzzHandler = new FizzBuzzEventHandler(BUZZ);
FizzBuzzEventHandler fizzBuzzHandler = new FizzBuzzEventHandler(FIZZ_BUZZ);
dw.handleEventsWith(fizzHandler, buzzHandler)
.then(fizzBuzzHandler);
RingBuffer ringBuffer = dw.start();Note there is a Wiki page on the Disruptor Wizard.
Other changes: performance improvements
As Martin mentions in his post, he's managed to significantly improve the performance (even more!) of the Disruptor in 2.0.
The short version of this is that there is a shiny new class, Sequence, which both takes care of the cache line padding, and removes the need for memory barriers. The cache line padding is now done slightly differently because, bless Java 7's little cotton socks, it managed to "optimise" our old technique away.
I'll leave you to read the details over there, in this post I just wanted to give a quick summary of the changes and explain why my old diagrams may no longer be correct.