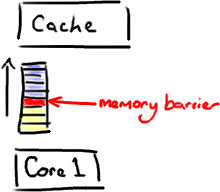
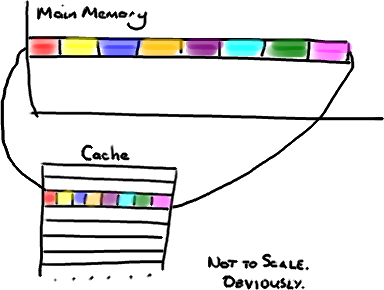
My recent slow-down in posting is because I've been trying to write a post explaining memory barriers and their applicability in the Disruptor. The problem is, no matter how much I read and no matter how many times I ask the ever-patient Martin and Mike questions trying to clarify some point, I just don't intuitively grasp the subject. I guess I don't have the deep background knowledge required to fully understand.
So, rather than make an idiot of myself trying to explain something I don't really get, I'm going to try and cover, at an abstract / massive-simplification level, what I do understand in the area. Martin has written a post going into memory barriers in some detail, so hopefully I can get away with skimming the subject.
Continue reading "Dissecting the Disruptor: Demystifying Memory Barriers"