Dalia and I (and a number of others!) had a conversation on our first Twitter Spaces session about "Comments: Good or Bad?". I argued for minimising the comments we have in our code, and in this blog post I want to explore how to do this in more detail.
I think this is one of those topics that can be framed badly. People who argue for comments are, rightly, arguing that one should be able to understand what the code does by reading it, and that adding comments can aid that readability. It might seem to people who feel this way that those who argue against comments are arguing against readable code, that are coming from a position of "I don't need no stinkin' comments, I'm smart enough to understand my code".
I was an avid commenter for years. I worked on lots of different types of code-bases, including legacy systems, apps using home-grown undocumented frameworks, overgrown prototypes, and so on. In other words, I worked in normal development environments. I was very keen on commenting code, because often these code bases were difficult to understand, or doing something they shouldn't in a place they shouldn't, and on top of that my memory is dreadful and comments seemed like a good way to remind myself what on earth I was thinking when I wrote that code.
When I was interviewed for LMAX, 10 years into my career, Martin Thompson mentioned that there were no comments in the code. I had heard of "self documenting code", but given my previous experiences did not see how this could work. Martin explained to me that comments could be an anti-pattern, since often people would update the code without updating the comment. I couldn't really argue with that, since I've seen that myself. He said that one should use method names and variable names that were helpful. I get that, but I didn't think that was enough. I'd seen some of the unusually long method names in the Spring framework (at least, they were unusually long when I first started working with Spring back in 2005/6) for example, but seen how the code that used Spring could still end up... interesting. Martin suggested that instead of writing a line-level comment, one could extract a private method with the same name as the comment you were about to write.
Whaaaat?
I had never, never, thought of doing small refactorings like that instead of writing comments. Previously, I had been in the camp of people who thought that those who argued against comments thought "I don't need no stinkin' comments", I hadn't seen how trying to avoid writing comments could move you to a mindset of "writing a comment is a sign of a design smell".
Stories and theories are all well and good, why don't we look at some examples?
Recently the JetBrains Java Developer Advocates (i.e. my team) have been working on a Spring Boot application. Well, actually two but that's neither here nor there. We have a method that creates a new restaurant booking (yes, restaurants, those places we used to eat at before the pandemic):
@PostMapping("/bookings")
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
if (restaurant == null) {
throw new RestaurantNotFoundException(booking.getRestaurantId());
}
if (restaurant.capacity() < booking.getNumberOfDiners()) {
throw new NoAvailableCapacityException("Number of diners exceeds available restaurant capacity");
}
if (!restaurant.openingDays().contains(booking.getDate().getDayOfWeek())) {
throw new RestaurantClosedException("Restaurant is not open on: " + booking.getDate());
}
List allByRestaurantIdAndDate = repository.findAllByRestaurantIdAndDate(booking.getRestaurantId(), booking.getDate());
int totalDinersOnThisDay = allByRestaurantIdAndDate.stream()
.mapToInt(Booking::getNumberOfDiners).sum();
if (totalDinersOnThisDay + booking.getNumberOfDiners() > restaurant.capacity()) {
throw new NoAvailableCapacityException("Restaurant all booked up!");
}
return repository.save(booking);
} This is fine... It works. How do we know that? Because we have unit and integration tests for it, a topic I hope to cover later. But there's something about this code that bothers me. That series of ifs looks a bit smelly. Validation code often looks like this, it's kinda fine if you know it's applying a series of checks, but you do have to read the code carefully to understand what each of those checks is. What's worse than not understanding immediately what they're doing is not knowing why they're doing it.
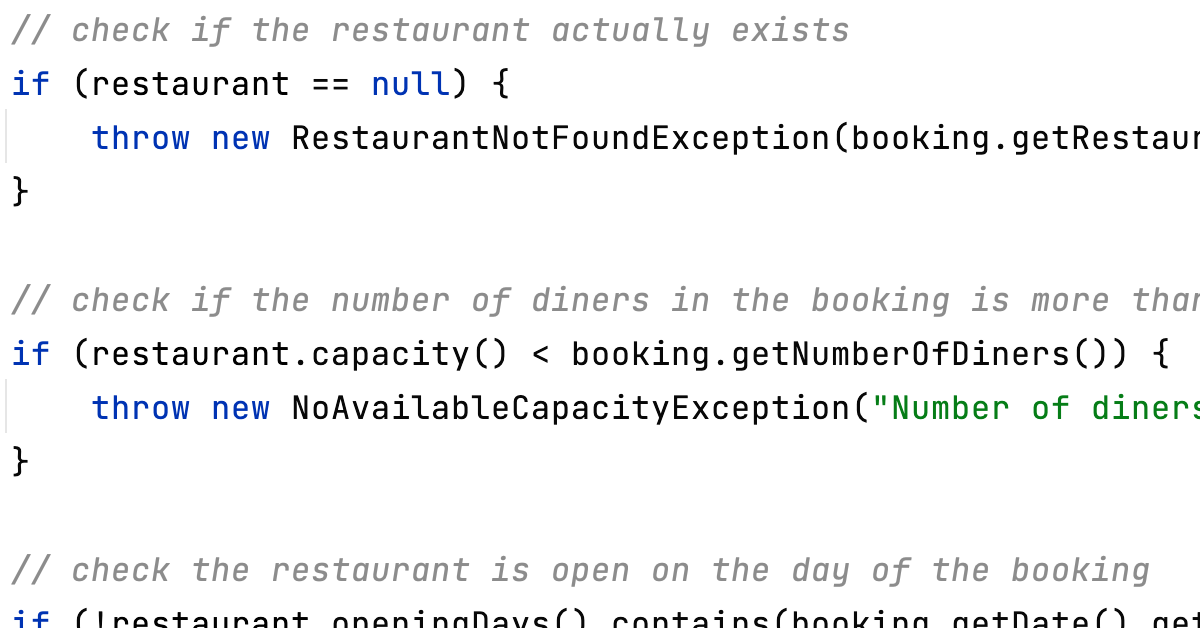
Taking a closer look at the code we could add some comments to clarify what's going on. Luckily, we have tried to make our variable names readable, and fortunately we chose to throw very specific custom Exceptions, which a) helps clients that are using the code to deal with each case individually but b) also helps us understand at this point in the code what the validation logic is:
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
// check if the restaurant actually exists
if (restaurant == null) {
throw new RestaurantNotFoundException(booking.getRestaurantId());
}
// check if the number of diners in the booking is more than the number of seats in the restaurant
if (restaurant.capacity() < booking.getNumberOfDiners()) {
throw new NoAvailableCapacityException("Number of diners exceeds available restaurant capacity");
}
// check the restaurant is open on the day of the booking
if (!restaurant.openingDays().contains(booking.getDate().getDayOfWeek())) {
throw new RestaurantClosedException("Restaurant is not open on: " + booking.getDate());
}
// find all the bookings for that day and check that with all the booked diners the restaurant still has space for the new booking diners
List allByRestaurantIdAndDate = repository.findAllByRestaurantIdAndDate(booking.getRestaurantId(), booking.getDate());
int totalDinersOnThisDay = allByRestaurantIdAndDate.stream().mapToInt(Booking::getNumberOfDiners).sum();
if (totalDinersOnThisDay + booking.getNumberOfDiners() > restaurant.capacity()) {
throw new NoAvailableCapacityException("Restaurant all booked up!");
}
// if we got this far, the booking is valid and we can save it
return repository.save(booking);
} This is good, I like that each clause is documented. But it's still a bit smelly, it feels very procedural. Again, validation code often looks like this, so maybe it's OK. But at this point I like to use IntelliJ IDEA's refactoring tools to start trying out different shapes for my code. This is something I learnt at LMAX: a) the IDE can safely refactor your code, reshaping it so not only does it still compile, but it also does the same thing as before and b) it's OK to reshape the code if it's not understandable for you. That's what shared code ownership is all about.
So let's extract each of these pieces into their own method (IntelliJ IDEA does something cool here, it (sometimes, don't ask me for the specifics cos I can't always get it to work) uses the comment as the generated method name:
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
// check if the restaurant actually exists
checkIfRestaurantExists(booking, restaurant);
// ... rest of the method as before....
// if we got this far, the booking is valid and we can save it
return repository.save(booking);
}
private void checkIfRestaurantExists(Booking booking, Restaurant restaurant) {
if (restaurant == null) {
throw new RestaurantNotFoundException(booking.getRestaurantId());
}
}Note that now the method is called more or less the same thing as the comment. It should be clear from the call-site, i.e. the place in our code where we're calling the method, what this method does.
I'm going to take a bit of a detour here because I don't really like the shape of the method - why does checkIfRestaurantExists need to take the booking as well? Well, it needs the restaurant ID from the booking to create a helpful error message. Since just the ID is needed and not the whole booking, I'm going to use "extract parameter" on booking.getRestaurantId() in IntelliJ IDEA to slightly re-shape this code:
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
// check if the restaurant actually exists
checkIfRestaurantExists(restaurant, booking.getRestaurantId());
// ... rest of the method as before....
}
private void checkIfRestaurantExists(Restaurant restaurant, String restaurantId) {
if (restaurant == null) {
throw new RestaurantNotFoundException(restaurantId);
}
}This looks better, but I'm actually a bit concerned about the name of the method. checkIfRestaurantExists tells me what it's doing, but it doesn't tell me what the outcome is. It sort of feels like maybe it should return something, like a boolean, but instead what it does is throw a runtime exception if the restaurant is null. We could document this method to show the contract:
/**
* Checks if the restaurant is null, and throws an Exception if it is
*
* @param restaurant the restaurant to check
* @param restaurantId the ID of the restaurant, used for error reporting if the restaurant is null.
* @throws RestaurantNotFoundException if the restaurant is null
*/
private void checkIfRestaurantExists(@Nullable Restaurant restaurant, String restaurantId) {
if (restaurant == null) {
throw new RestaurantNotFoundException(restaurantId);
}
}This feels a tiiiiiny bit like overkill:
- The comment is longer than the method
- The description of what the method does (throws an Exception if the restaurant is null) is repeated twice in the documentation and, of course, is "readable" from the method contents itself and
- Javadoc on a private method is not encouraged.
Because of point 2, as soon as the functionality changes even slightly, this whole comment needs to be completely re-written as it's very closely coupled to the implementation. This is what people mean when they say documentation and comments "rot", it can easily get out of sync with the code.
I do like adding @Nullable to the restaurant parameter though, that feels like a helpful piece of "documentation".
What if, instead, we changed the name of the method to be even more descriptive, although general enough to encompass other types of validation if they come along later?
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
// check if the restaurant actually exists
throwExceptionIfRestaurantNotValid(restaurant, booking.getRestaurantId());
// ... rest of the method as before....
}
private void throwExceptionIfRestaurantNotValid(@Nullable Restaurant restaurant, String restaurantId) {
if (restaurant == null) {
throw new RestaurantNotFoundException(restaurantId);
}
}This method name is even more helpful, and removes the need for the comment altogether. One possible side-effect of this refactoring is that I could test just this specific piece of logic, the throwExceptionIfRestaurantNotValid method, with a unit test (yes, it would either need to be made package-private or one would have to use a test framework that supported testing private methods). There's probably no need for it at this stage, but as soon as the logic becomes more than this simple check, I might want a series of unit tests to document exactly what is expected of the method: what's valid and invalid input, what the expected behaviour is. These unit tests are yet another good way to "document" the code, they should state the expectations of how it behaves and maybe even why.
We can apply this sort of refactoring to all the sections of the method:
public Booking createBooking(@RequestBody Booking booking, RestTemplate restTemplate) {
// In a "real" environment this would at the very least be a property/environment variable, but ideally something like Service Discovery like Eureka
Restaurant restaurant = restTemplate.getForObject("http://localhost:8080/restaurants/" + booking.getRestaurantId(), Restaurant.class);
throwExceptionIfRestaurantNotValid(restaurant, booking.getRestaurantId());
throwExceptionIfBookingHasMoreDinersThanRestaurantHasSeats(booking, restaurant);
throwExceptionIfRestaurantIsClosedOnBookingDate(booking, restaurant);
throwExceptionIfRestaurantDoesNotHaveEnoughSpaceOnThatDate(booking, restaurant);
// if we got this far, the booking is valid and we can save it
return repository.save(booking);
}
private void throwExceptionIfRestaurantNotValid(@Nullable Restaurant restaurant, String restaurantId) {
if (restaurant == null) {
throw new RestaurantNotFoundException(restaurantId);
}
}
private void throwExceptionIfBookingHasMoreDinersThanRestaurantHasSeats(Booking booking, Restaurant restaurant) {
if (restaurant.capacity() < booking.getNumberOfDiners()) {
throw new NoAvailableCapacityException("Number of diners exceeds available restaurant capacity");
}
}
private void throwExceptionIfRestaurantIsClosedOnBookingDate(Booking booking, Restaurant restaurant) {
if (!restaurant.openingDays().contains(booking.getDate().getDayOfWeek())) {
throw new RestaurantClosedException("Restaurant is not open on: " + booking.getDate());
}
}
private void throwExceptionIfRestaurantDoesNotHaveEnoughSpaceOnThatDate(Booking booking, Restaurant restaurant) {
// find all the bookings for that day and check that with all the booked diners the restaurant still has space for the new booking diners
List allByRestaurantIdAndDate = repository.findAllByRestaurantIdAndDate(booking.getRestaurantId(), booking.getDate());
int totalDinersOnThisDay = allByRestaurantIdAndDate.stream().mapToInt(Booking::getNumberOfDiners).sum();
if (totalDinersOnThisDay + booking.getNumberOfDiners() > restaurant.capacity()) {
throw new NoAvailableCapacityException("Restaurant all booked up!");
}
} It still feels pretty procedural to me, but there are advantages:
- The
createBookingmethod now "documents" the validation steps taken before the booking is accepted, via the calls to the methods - The
createBookingmethod is shorter - Each check is separated clearly
- Each
throwException...method can be tested individually if required
Interestingly, after this refactoring I can now see a few changes that I might like to make, although they're more a matter of taste:
-
I think I'd like to merge
throwExceptionIfBookingHasMoreDinersThanRestaurantHasSeatsandthrowExceptionIfRestaurantDoesNotHaveEnoughSpaceOnThatDate, since they throw the same exception. This suggests a caller doesn't really care about the difference between these two checks, all that matters is that the number of diners is compared against the restaurant capacity (e.g.throwExceptionIfRestaurantDoesNotHaveCapacity- doesn't matter why they don't have capacity). I originally separated these as one check involves a database call and the other does not, so they don't have the same performance. But as long as the cheaper call is made first (so it fails fast if it can) I think the probably could be merged into one method. -
I would like a more object-oriented validator pattern. Partly because if these methods were split into validator classes they could be reused (but let's not go crazy because we don't know yet if they ever would be reused), but mostly because it feels more testable that way. Each validator would have a series of happy- and unhappy-path tests to document exactly what is and is not valid input and expected behaviour. If we put all those tests into the BookingControllerTest (unit test) it might get big very fast. Big test classes with many test cases suggest that the class under test has too many responsibilities.
Anyway. At this point I've enjoyed myself playing with code and moving it around, and have slightly moved away from the original point of the post. What I hope I've shown is that it's possible to reduce the number of comments in your code by extracting functionality that needs to be documented into its own method with a descriptive method name.
In order to feel comfortable doing that in your code you may need:
- Shared code ownership. You are "allowed" to make changes to code that maybe you didn't write.
- An existing set of automated tests, to a) make sure any changes you make haven't broken anything and b) to maybe refer to in order to understand the intent of the functionality
- An IDE that can automatically safely refactor code for you. Of course, you can use Martin Fowler's excellent explanations of how to perform refactoring step by step. But if your IDE can just do it for you, it's much faster to quickly experiment with reshaping your code.
Note that in this example we did not remove all the comments in the code. I personally prefer not to have comments in my code, because I feel they're usually a sign that something needs to change in the code. However, as you can see, I'm not a strict no-commenter. But I do prefer my comments to either talk about the why, not the how, and/or to be notes about things that cannot be inferred by the code.
In Summary
Developers should create code that the next developer can understand. Sometimes, comments are a safe, simple way to leave the code better than you found it. Sometimes, extracting sections of code into a well-named method can be an alternative way of doing this, with the added benefit that a) you can test this method individually and b) it may help you to spot smells in your code or see places for further refactoring or simplification.
Postscript:
After writing all of the above I spent a few hours messing around moving validation into validator classes (see the code on GitHub) and then trying to find a design pattern that lets me apply all the validators in a nice way. It's not super easy to do with the design I've used for Validators, because each validator takes different arguments and the BookingController is still responsible for getting all the data (e.g. bookings) and passing them into the validators, so there's no easy way to treat all validators equally. Maybe there is a nice pattern, but I realised that with this experimentation I've wandered far from the original purpose of this blog post!
3 thoughts on “Do we need comments in our code?”
Moving the code into methods makes the main method more readable, I agree, but it also fragments the code. You have to jump from method to method (or validation class to validation class) to see what actually is checked. So the question is if the simple if-statements warrant the scaffolding of additional methods or even classes.
Also, just like there is risk of “comment rot”, there also is risk of “name rot”. The method or class may say IfBookingHasMoreDinersThanRestaurantHasSeats, but maybe someone sneaked in a check for date as well. But unlike comments, method names are referenced, so changing it may be more cumbersome than just changing a comment.
Personally, I try to find a balance between comments and refactoring. First of all because I’m not a compiler, I read natural language easier than code. Second because I often code out functionality in comments first, and then write the associated code. To me, DRY is a good reason put things in a method (albeit not always), complexity can be as well, but simple if statements very seldom.
I’m not really a fan of the method bloat that this leads to, so the approach that I’ve taken to solving this problem is typically to do all the checks, store them as booleans with descriptive names or into a dictionary. This results in the validation method still being self-contained, the code is maximally self-documenting, and you can make decisions about how to handle multiple failure types happening together.
An example of that last item is that you can collate *everything* that’s wrong and return that to the user instead of forcing them to iterate through multiple failure modes. This is the difference between “You must set a password. Now you must provide an address. Now you must provide a booking time” and “Please provide a password, address, and booking time”.
Good points Trisha. 🤜🤛