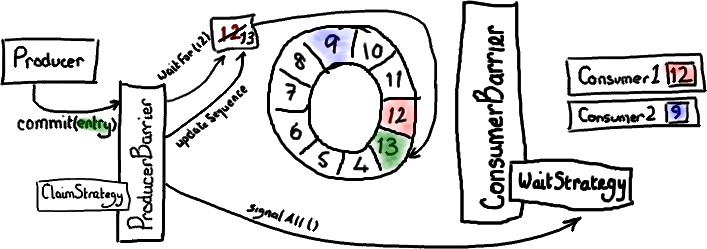
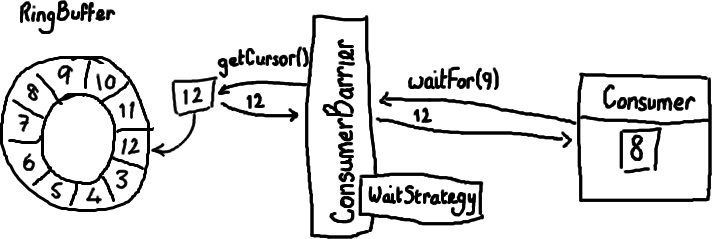
So now I've covered the ring buffer itself, reading from it and writing to it.
Logically the next thing to do is to wire everything up together.
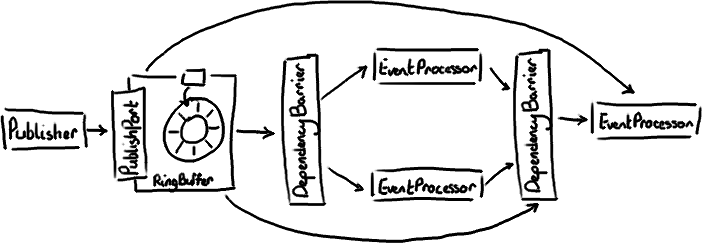
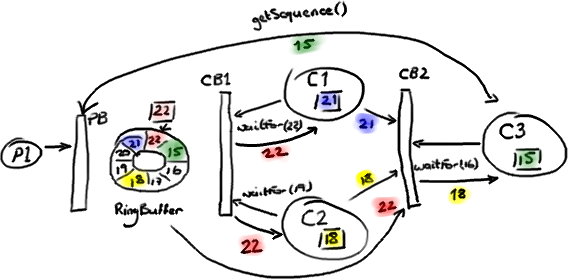
I talked about multiple producers - they have the producer barrier to keep them in order and under control. I've talked about consumers in a simple situation. Multiple consumers can get a little more involved. We've done some clever stuff to allow the consumers to be dependent on each other and the ring buffer. Like a lot of applications, we have a pipeline of things that need to happen before we can actually get on with the business logic - for example, we need to make sure the messages have been journalled to disk before we can do anything.
The Disruptor paper and the performance tests cover some basic configurations that you might want. I'm going to go over the most interesting one, mostly because I needed the practice with the graphics tablet.
Read more