Martin recently announced version 2.0 of the Disruptor - basically there have been so many changes since we first open-sourced it that it's time to mark that officially. His post goes over all the changes, the aim of this article is to attempt to translate my previous blog posts into new-world-speak, since it's going to take a long time to re-write each of them all over again. Now I see the disadvantage of hand-drawing everything.
disruptor-docs
Dissecting the Disruptor: Demystifying Memory Barriers
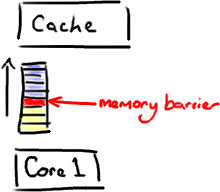
My recent slow-down in posting is because I've been trying to write a post explaining memory barriers and their applicability in the Disruptor. The problem is, no matter how much I read and no matter how many times I ask the ever-patient Martin and Mike questions trying to clarify some point, I just don't intuitively grasp the subject. I guess I don't have the deep background knowledge required to fully understand.
So, rather than make an idiot of myself trying to explain something I don't really get, I'm going to try and cover, at an abstract / massive-simplification level, what I do understand in the area. Martin has written a post going into memory barriers in some detail, so hopefully I can get away with skimming the subject.
Dissecting the Disruptor: Why it’s so fast (part two) – Magic cache line padding
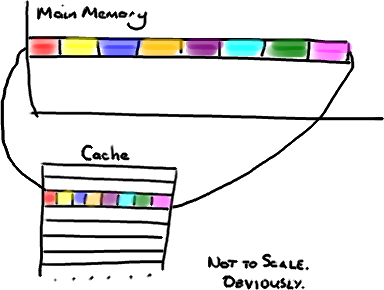
We mention the phrase Mechanical Sympathy quite a lot, in fact it's even Martin's blog title. It's about understanding how the underlying hardware operates and programming in a way that works with that, not against it.
We get a number of comments and questions about the mysterious cache line padding in the RingBuffer, and I referred to it in the last post. Since this lends itself to pretty pictures, it's the next thing I thought I would tackle.
Dissecting the Disruptor: Why it’s so fast (part one) – Locks Are Bad
Martin Fowler has written a really good article describing not only the Disruptor, but also how it fits into the architecture at LMAX. This gives some of the context that has been missing so far, but the most frequently asked question is still "What is the Disruptor?".
I'm working up to answering that. I'm currently on question number two: "Why is it so fast?".
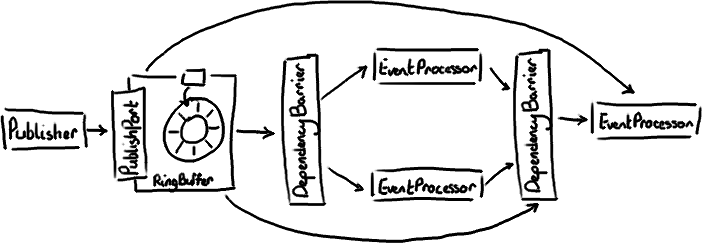
Dissecting the Disruptor: Wiring up the dependencies
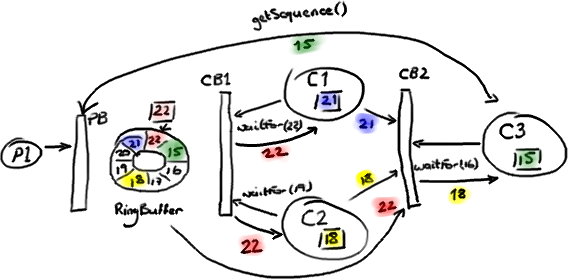
So now I've covered the ring buffer itself, reading from it and writing to it.
Logically the next thing to do is to wire everything up together.
I talked about multiple producers - they have the producer barrier to keep them in order and under control. I've talked about consumers in a simple situation. Multiple consumers can get a little more involved. We've done some clever stuff to allow the consumers to be dependent on each other and the ring buffer. Like a lot of applications, we have a pipeline of things that need to happen before we can actually get on with the business logic - for example, we need to make sure the messages have been journalled to disk before we can do anything.
The Disruptor paper and the performance tests cover some basic configurations that you might want. I'm going to go over the most interesting one, mostly because I needed the practice with the graphics tablet.
Dissecting the Disruptor: Writing to the ring buffer
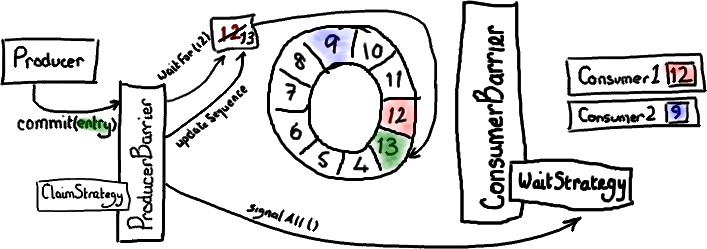
This is the missing piece in the end-to-end view of the Disruptor. Brace yourselves, it's quite long. But I decided to keep it in a single blog so you could have the context in one place.
The important areas are: not wrapping the ring; informing the consumers; batching for producers; and how multiple producers work.
Dissecting the Disruptor: How do I read from the ring buffer?
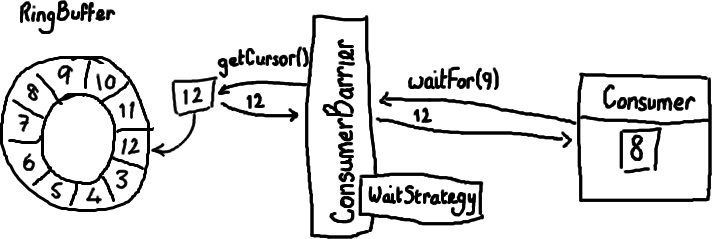
The next in the series of understanding the Disruptor pattern developed at LMAX.
After the last post we all understand ring buffers and how awesome they are. Unfortunately for you, I have not said anything about how to actually populate them or read from them when you're using the Disruptor.
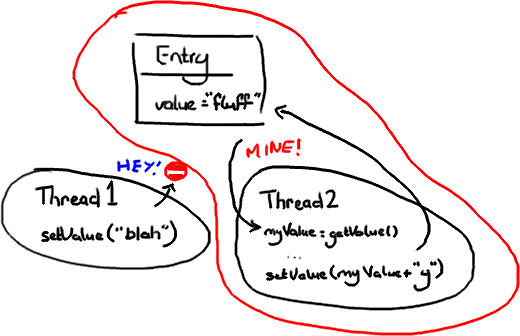
Dissecting the Disruptor: What’s so special about a ring buffer?
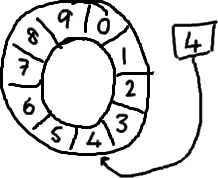
Recently we open sourced the LMAX Disruptor, the key to what makes our exchange so fast. Why did we open source it? Well, we've realised that conventional wisdom around high performance programming is... a bit wrong. We've come up with a better, faster way to share data between threads, and it would be selfish not to share it with the world. Plus it makes us look dead clever.
On the site you can download a technical article explaining what the Disruptor is and why it's so clever and fast. I even get a writing credit on it, which is gratifying when all I really did is insert commas and re-phrase sentences I didn't understand.
However, I find the whole thing a bit much to digest all at once, so I'm going to explain it in smaller pieces, as suits my NADD audience.
First up - the ring buffer. Initially I was under the impression the Disruptor was just the ring buffer. But I've come to realise that while this data structure is at the heart of the pattern, the clever bit about the Disruptor is controlling access to it.